SIL-UND 2010 COMPUTATIONAL SYNTAX AND MORPHOLOGY
Lecture of Week 6 Class 3
Corpus Analysis using WordSmith
Corpora with concordancers are a useful tool for language analysts especially when looking to improve the quality of the produced analyses (and/or translations).
Ways in which the exploration of corpora can help with text processing and analysis:
-by providing info about collocates of a given term
-by helping analysts choose between candidate terms
-by enabling analysts to validate intuitive decisions
-by indicating unfamiliar uses in a concordance
-by accidentally finding relevant information
WordSmith (WS) is one of the most comprehensive corpus analysis packages which comes with a concordance facility. This facility allows for:
-finding all occurrences of a search word or a search pattern
-display them in the center of the screen along with surrounding context (the so called KWIC display)
Exercise 1:
-Open WS and select “Concord”
-Compile a small corpus of text files and open it into the Concord window – WS will let you select the files you wish to use as your corpus
-Select a keyword to search in your corpus
-Examine output
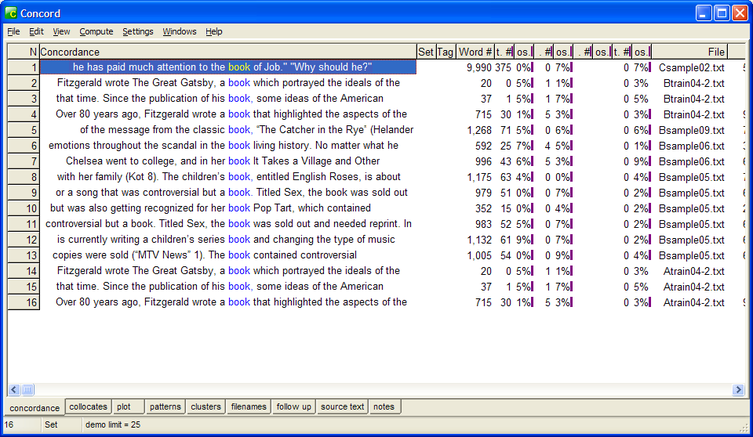
Fig. 1: WS concord output for the search term “book” in a small corpus of 85 text files
Exercise 2:
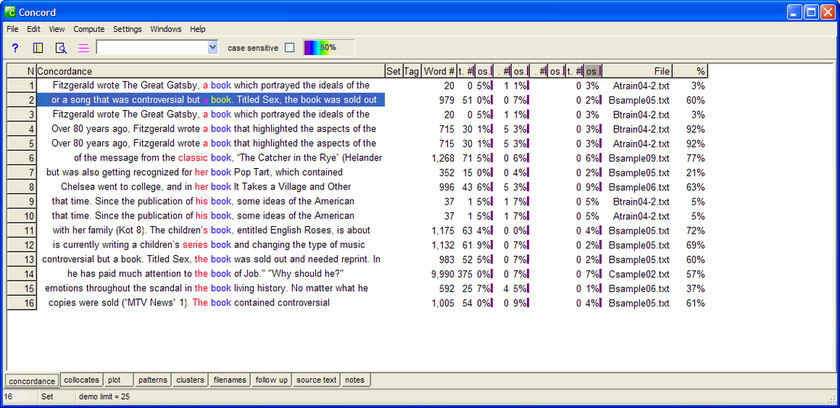
Now let's play with WS's sorting capabilities; since the seach word is a noun (book) we can sort the concordance output by ordering the word immediately preceding it
(i.e. on the left of it) alphabetically. This sort would help to locate suitable specifiers (adj's etc.) that collocate with the search word. Check the sorted output in Fig. 2:
Now let's play with WS's sorting capabilities; since the seach word is a noun (book) we can sort the concordance output by ordering the word immediately preceding it
(i.e. on the left of it) alphabetically. This sort would help to locate suitable specifiers (adj's etc.) that collocate with the search word. Check the sorted output in Fig. 2:
Fig. 2: WS concord output sorted alphabetically according to the word in the left of “book”
By double-clicking on a line in the Concord window, you can view it in its full context as in Fig. 3, which displays line 1 of figure 2 in its actual context.
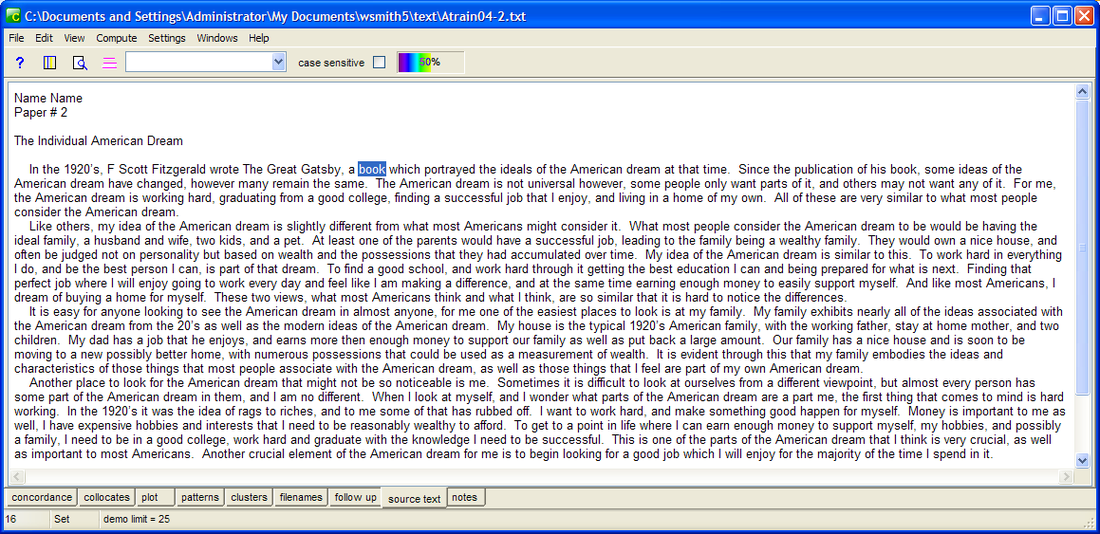
Fig. 3: WS concord output display showing a specified line in its full context
Slightly more complex searches would allow for multiple search patterns at the same time. For instance, let's say that we wish to investigate the behavior of under as a prefix and as a preposition in a specified corpus. We can search for the following combination of patterns:
under*/under
The above will search for both under as a prefix and as a preposition. Sorting by R1 can help us look into the results, as in Fig. 4:
under*/under
The above will search for both under as a prefix and as a preposition. Sorting by R1 can help us look into the results, as in Fig. 4:
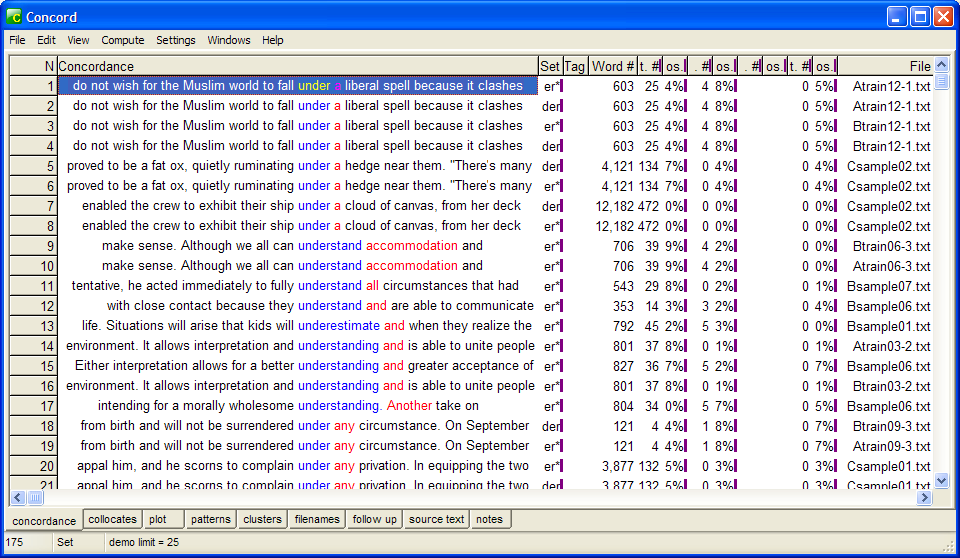
Fig. 4: WS concord output for the search pattern “under*/under”
You can play around with adding more sort options in your output based on a wider context. Here's a display with wider context sort:
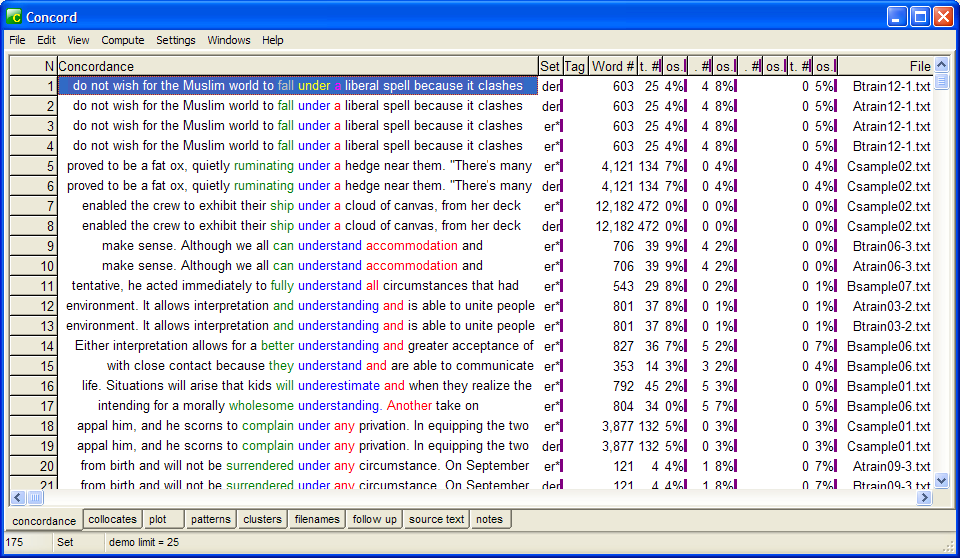
Fig. 5: WS concord output sorted primarily for R1 and secondarily for L1
The WS demo limit in line display is 25 but if you save the output, the entire file will be saved. For now, try different sorts so you can get a sense of the data in the limited window frame of 25 lines.
Strategies to increase recall:
When working with search strings it is always necessary to develop search strategies for the discovery of that part of the data that we know are 'out there' but we haven't reached yet, or even -one step further- the data that we don't even know (or suspect) are out there.
“Fuzzy” searches can increase the likelihood of “accidentally” finding relevant information, especially if the original query didn't yield the results we expected. WS's Advanced Search feature is especially useful for implementing this type of creative searches as it facilitates concordancing with contextually relevant search words. Like with using proximity operators in search engines, you can specify a context word (or words) that must (or must not) appear within a certain number of words around the search string.
For instance, looking for compound nouns when unsure about whether they occur alone and in what form in a specified corpus, you may want to search (e.g.) for afternoon and after noon as well as awesome and awe*. A fuzzier search would allow for awe* as a search pattern and s* as the context word (for awestruck, awe-struck, awe-stricken) and even awe* *s* (for awe-inspired).
Exercise 3:
Create an advanced search that suits your corpus.
WordList:
To explore synonyms or partial synonyms in a corpus, we need a tool to help us differentiate between them. WS includes a WordListtool, which can show all the words in the corpus displayed in alphabetical order or in frequency order. Fig 6. below shows the output of the corpus used above sorted by frequency:
Strategies to increase recall:
When working with search strings it is always necessary to develop search strategies for the discovery of that part of the data that we know are 'out there' but we haven't reached yet, or even -one step further- the data that we don't even know (or suspect) are out there.
“Fuzzy” searches can increase the likelihood of “accidentally” finding relevant information, especially if the original query didn't yield the results we expected. WS's Advanced Search feature is especially useful for implementing this type of creative searches as it facilitates concordancing with contextually relevant search words. Like with using proximity operators in search engines, you can specify a context word (or words) that must (or must not) appear within a certain number of words around the search string.
For instance, looking for compound nouns when unsure about whether they occur alone and in what form in a specified corpus, you may want to search (e.g.) for afternoon and after noon as well as awesome and awe*. A fuzzier search would allow for awe* as a search pattern and s* as the context word (for awestruck, awe-struck, awe-stricken) and even awe* *s* (for awe-inspired).
Exercise 3:
Create an advanced search that suits your corpus.
WordList:
To explore synonyms or partial synonyms in a corpus, we need a tool to help us differentiate between them. WS includes a WordListtool, which can show all the words in the corpus displayed in alphabetical order or in frequency order. Fig 6. below shows the output of the corpus used above sorted by frequency:
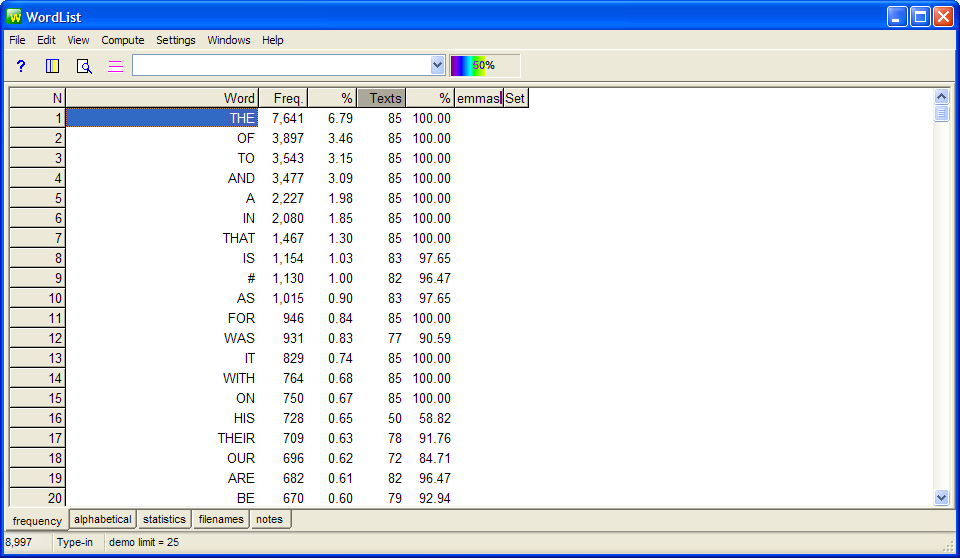
Fig. 6: WS WordList output sorted in frequency order
Notice that the bottom left hand corner shows that there are 8,997 different words in the corpus. The output in Fig. 6 is not very useful in terms of synonyms. Let's sort it in alphabetical order.
Exercise 4:
Repeat the above procedure with your own corpus and sort the output alphabetically. Do you notice any interesting frequency differences among synonyms?
Collocates:
Although counting occurrences of synonyms in a corpus may tell us a bit about their preferred usage, it does not help the translator or analyst of the corpus to make subtle distinctions with regard to their meanings. For this, the collocates display is more useful. To create such a list, choose Concord on the initial WS window and select File-> New from the drop-down menu; on the Getting Started pop-up window, fill in the slots with the search term and the context term(s) in Search Word and Advanced tabs respectively.
Compare the concordance and collocates tables for the same output on a search for book below:
Exercise 4:
Repeat the above procedure with your own corpus and sort the output alphabetically. Do you notice any interesting frequency differences among synonyms?
Collocates:
Although counting occurrences of synonyms in a corpus may tell us a bit about their preferred usage, it does not help the translator or analyst of the corpus to make subtle distinctions with regard to their meanings. For this, the collocates display is more useful. To create such a list, choose Concord on the initial WS window and select File-> New from the drop-down menu; on the Getting Started pop-up window, fill in the slots with the search term and the context term(s) in Search Word and Advanced tabs respectively.
Compare the concordance and collocates tables for the same output on a search for book below:
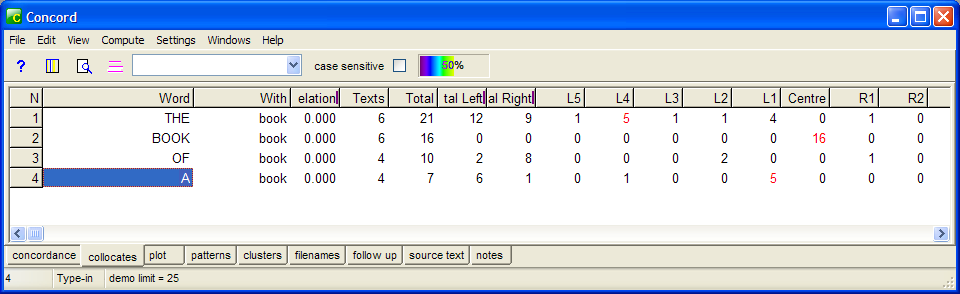
Fig. 7: WS Concordance output for “book”
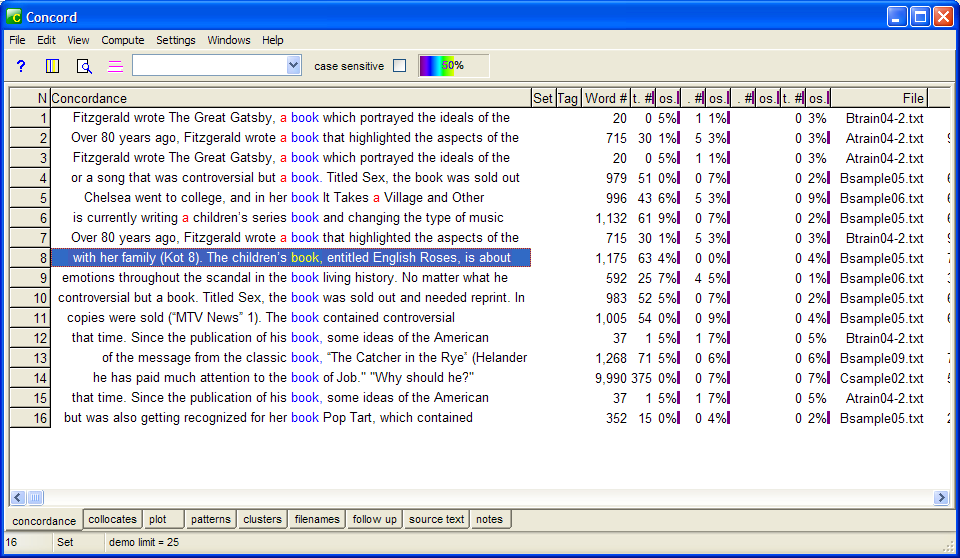
Fig. 8: WS Collocates output for “book”
The collocates display in Fig. 8 shows the words that collocate with book in the specified corpus, arranged in order of frequency (notice columns “total left” and “total right”). Of the 4 words that occur within the surrounding neighborhood of the search word (i.e. within a span of 5 to the left or 5 to the right) we see that the is the most frequent collocate, occurring 21 times. We also see from the L1 & R1 columns that a appears immediately to the left of the search term (5 occurrences). However there are no occurrences of book in the immediate neighborhood of book.
This is a rather trivial case that shows just how much information we can gather from a display of collocates.
Exercise 5:
Repeat the above procedure within your own corpus and create a display of collocates for your search term. What does the resulting collocates display tell you about some of the prevalent patterns in your corpus?
This is a rather trivial case that shows just how much information we can gather from a display of collocates.
Exercise 5:
Repeat the above procedure within your own corpus and create a display of collocates for your search term. What does the resulting collocates display tell you about some of the prevalent patterns in your corpus?
